
APK mining, or data mining, is the process of exploring and reading the code behind Pokémon GO. We’ve been doing this for a while already, and so have others, namely TheSilphRoad. This is the first and, as far as we know, the only step by step guide on the Internet on how to do it.
For this guide, you will need the following:
- a zip tool, like 7zip
- a copy of the latest Pokémon GO APK, which is available at APK Mirror
- a good text editor with support for RegEX like Sublime Text, Notepad++ or Atom
- a Hex editor that can convert from Hex to ASCII, like HxD
In this guide you will learn the following:
- open the APK and extract Pokémon GO metadata
- decode the metadata file from HEX to ASCII format
- understand and remove useless parts of the decoded file
- and finally: data mine and explore the code behind Pokémon GO using your text editors Search and Replace with RegEX (regular expressions)
If this sounds difficult, or even dangerous, don’t be afraid – it’s none of that! It’s just a rather lengthy process that sounds harder than it really is! Let’s start! 🙂
1. Extracting Pokémon GO metadata
This step is very simple. Download the APK and open it with 7zip (or any other zip tool). The 0.55.0 APK that was used for this guide is around 81.4Mb large and includes around 7Mb of metadata that’s interesting for exploration.
The metadata file we’re looking for is situated here:
assetsbinDataManagedMetadataglobal-metadata.dat
Just drag and drop the file outside of the archive. At this point, we are going to use HxD so make sure you installed it, or if not, install it now.
2. Decoding the global-metadata.dat to ASCII
After extracting the metadata file from the APK, open HxD and open the metadata file with it. Make sure your decoding configuration says the following:
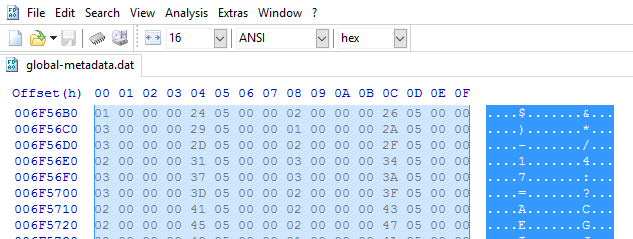
Now select all from the right column and copy it into a text editor of your choice. We use Sublime Text 3 due to high performance and good RegEX support.
3. Understanding and trimming the decoded metadata file
At this point, you’re close to starting your data mine, however, there is still some infrastructure work to do. First, we need to understand the file and remove useless parts.
The decoded file is structured in the following fashion:
- short “dotted” preamble, can be removed completely
- exception log, can be removed completely
- code dumps and metadata, do not remove
- very long “dotted” trail, can be removed completely
You should remove these parts of the file, or copy the number 3. part to a new file, as it will improve performance and speed of mining dramatically. You will recognise the dotted areas as they are unreadable and have a huge amount of dotted strings:

As for the exception log, it runs all the way from the end of first “dotted” area to the place where “mscorlib.dll” appears. Our process is to remove the first “dotted” area then find “mscorlib.dll” and remove everything before that.
The interesting part of the file is now yours.
Let’s recap this step:
Remove everything from start of file to first occurrence of “mscorlib.dll”. Remove everything that looks like a dotted area from the bottom of the file.
4. Formatting the file
And now, the fun part! In order to understand the file, we first need to format it using RegEXs! Open Search and Replace in your text editor, turn on RegEX mode and turn on Case Sensitivity. This is how it looks in Sublime Text 3:
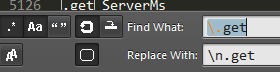
And now, use the following expressions to format the file:
| Find What | Replace What | Result |
|---|---|---|
| .get | n.get | Every string starting with .get is now in a new line |
| .set | n.set | Every string starting with .set is now in a new line |
| . | n. | Break everything that starts with a dot in a new line |
| .ACTIVITY | n.ACTIVITY | Format Activities in new lines |
| .ITEM_ | n.ITEM_ | Format Item, Item effects and categories in new lines |
| .BADGE | n.BADGE | Format Badges in new lines |
| .V0 | n.V0 | Format Moves and Pokemon families in new lines |
We always use the bold strings to format and to data mine. The other ones are used for data extraction if needed.
In all honesty, you can format the file even further, but using these few expressions helps me get the gist in the initial data mining. If you’re interested to learn more about the concept of Regular Expressions, take a look at regexr where you can learn and explore regular expressions further.
5. Finding the truth
We’ve successfully extracted the metadata, decoded it and formatted it for exploration. Where do you go from here is on you – it’s all about reading comprehension now. Read, explore, learn, bookmark and be wise.
You now possess a powerful set of information. Use it wisely.

{kind=link}